主成分分析(PCA)
主成分分析(Principal Component Analysis,PCA)将代谢物变量按一定的权重通过线性组合后产生新的特征变量,通过主要新变量(主成分)对各组数据进行归类,去除重复性差的样本(离群样本)和异常样本(在置信区间——Hotelling T2椭圆外的样本)。
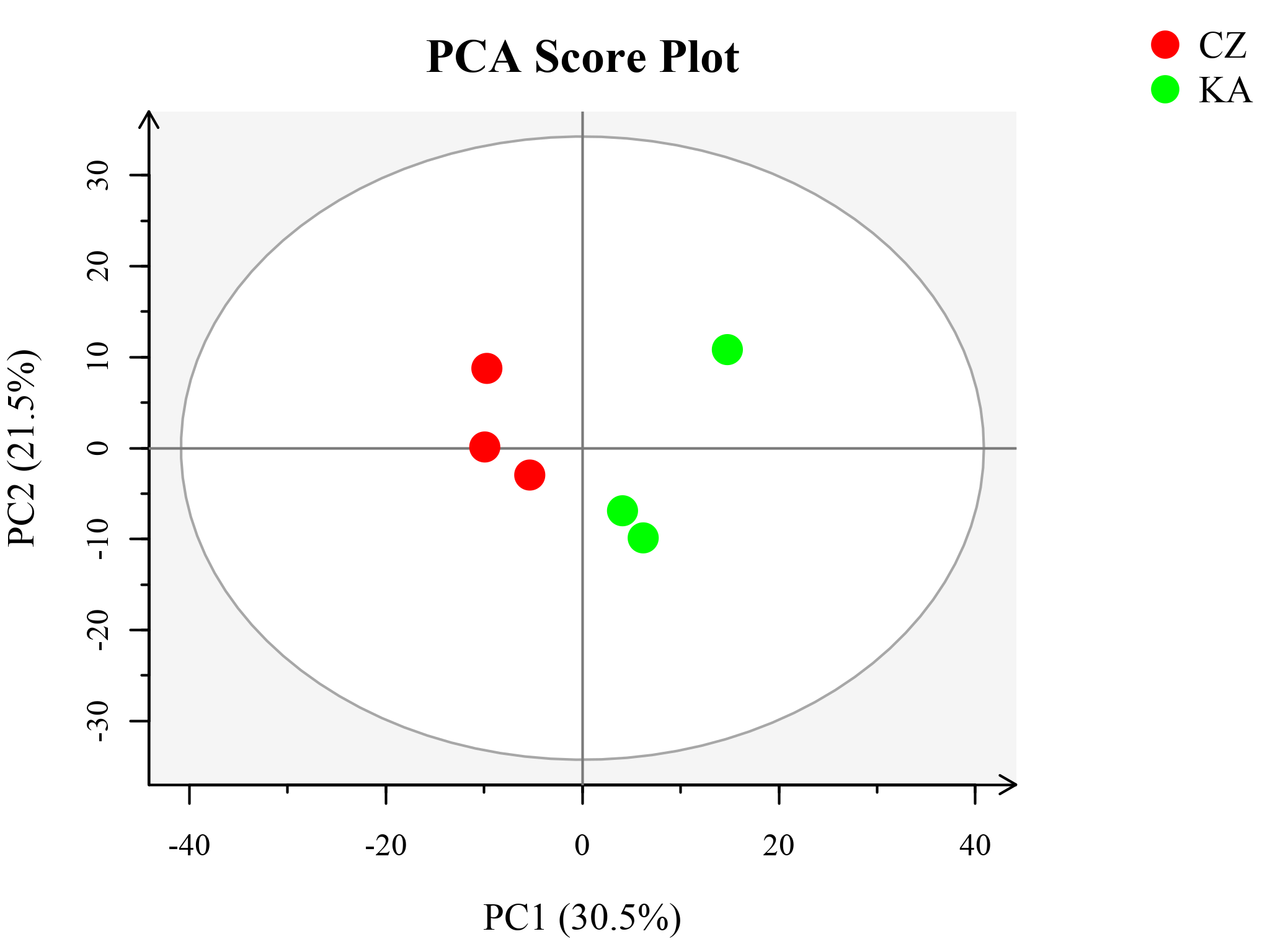
因无外加人为因素,得到的PCA模型反映了代谢组数据的原始状态,有利于掌握数据的整体情况并对数据从整体上进行把握,尤其是有利于发现和剔除异常样品,并提高模型的准确性。经过PCA计算出的数学模型是否可靠需要进行严格的验证——不可靠的数学模型不仅不能很好地描述代谢组学数据特点,还可能严重影响正确结果的获得甚至误导分析结果。
模型的交叉验证主要参考R2X等参数,R2X是模型的可解释度。通常情况下,R2高于0.5较好。
各个样品在各个主成分的得分就是其在计算的数学模型中的空间坐标,直观地反映了各个样品在数学模型空间中的分布情况。从PCA得分图可观察样品的聚集、离散程度。样品分布点越靠近,说明这些样品中所含有的变量/分子的组成和浓度越接近;反之,样品点越远离,其差异越大。