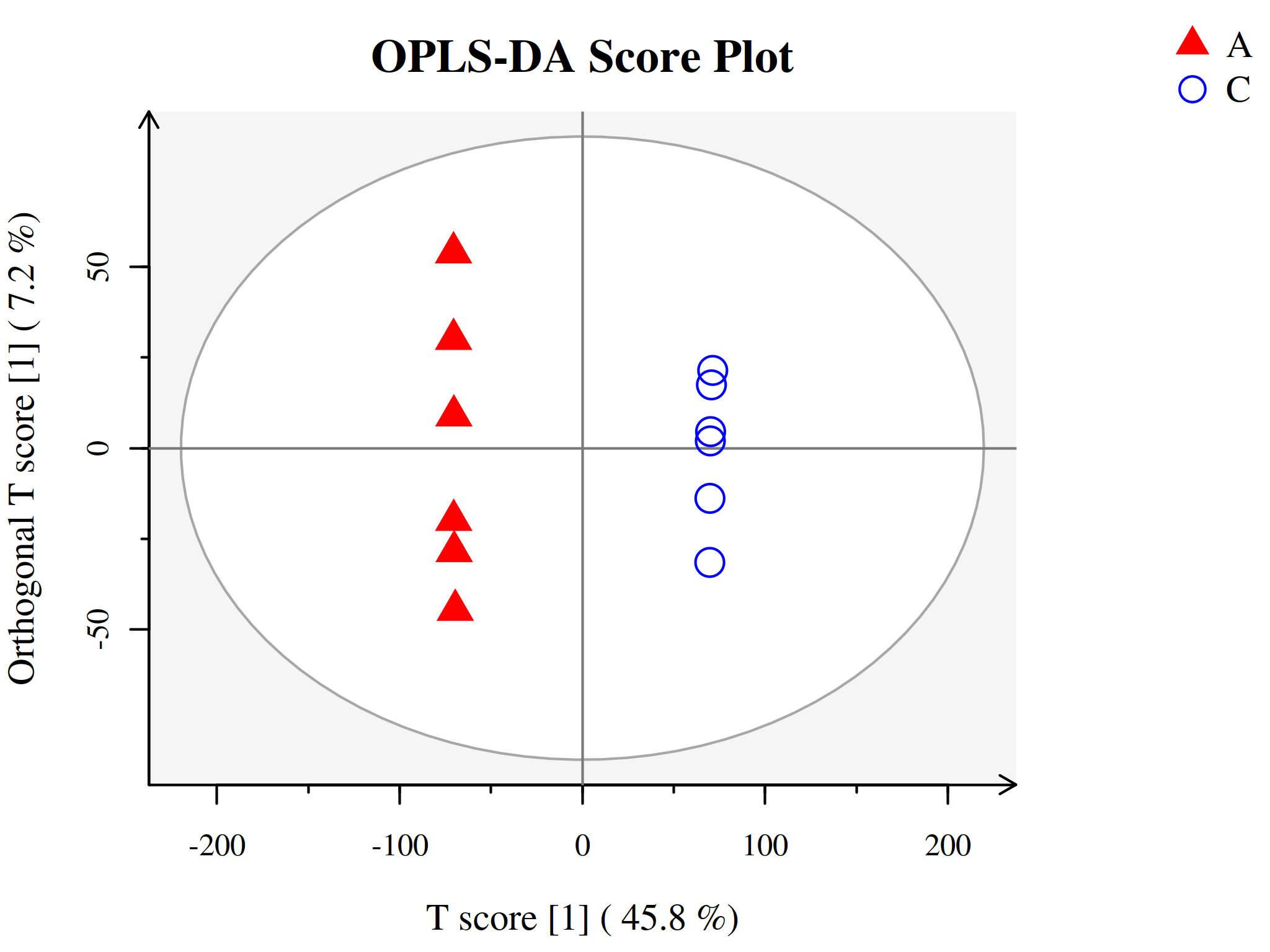
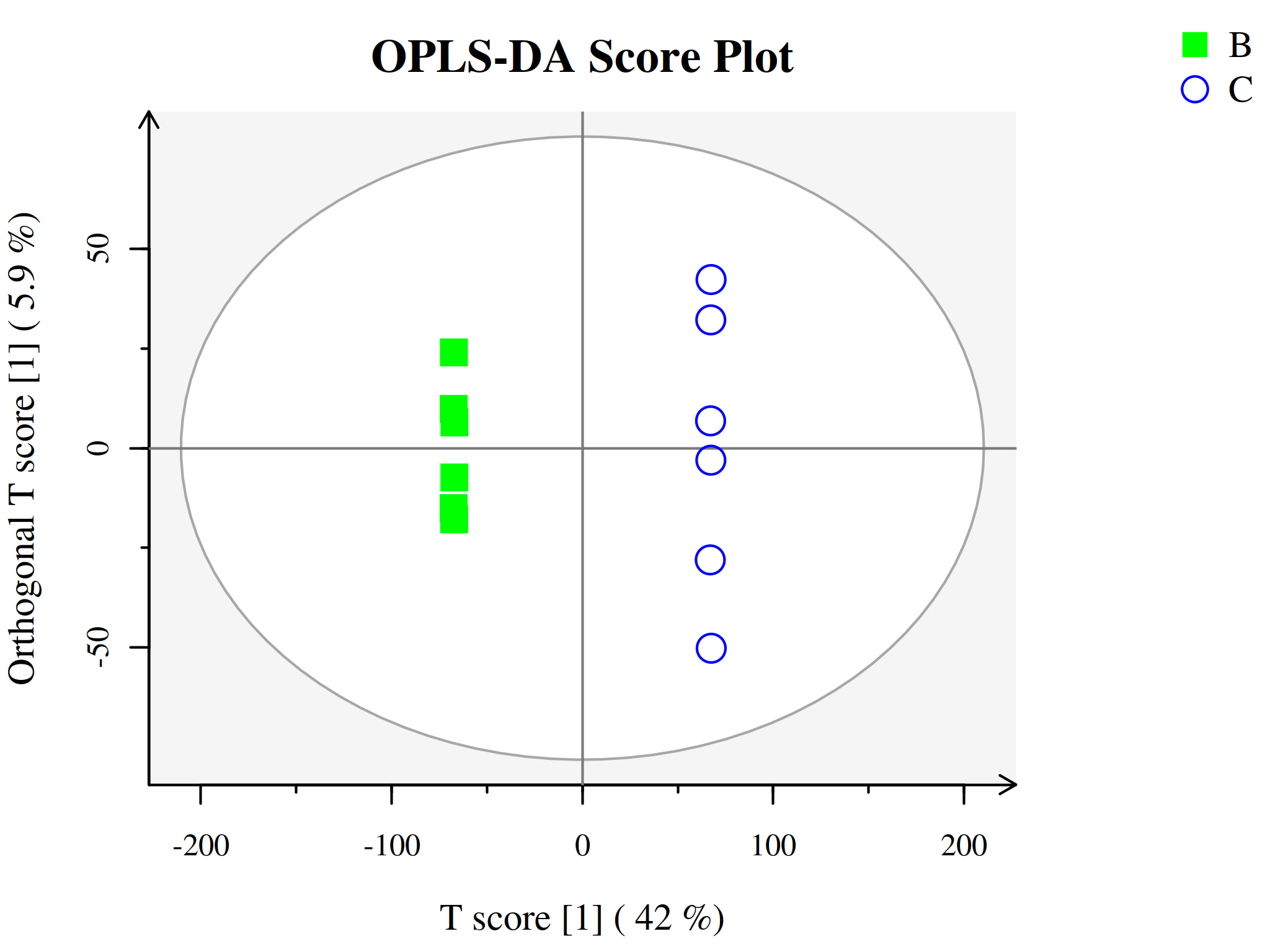
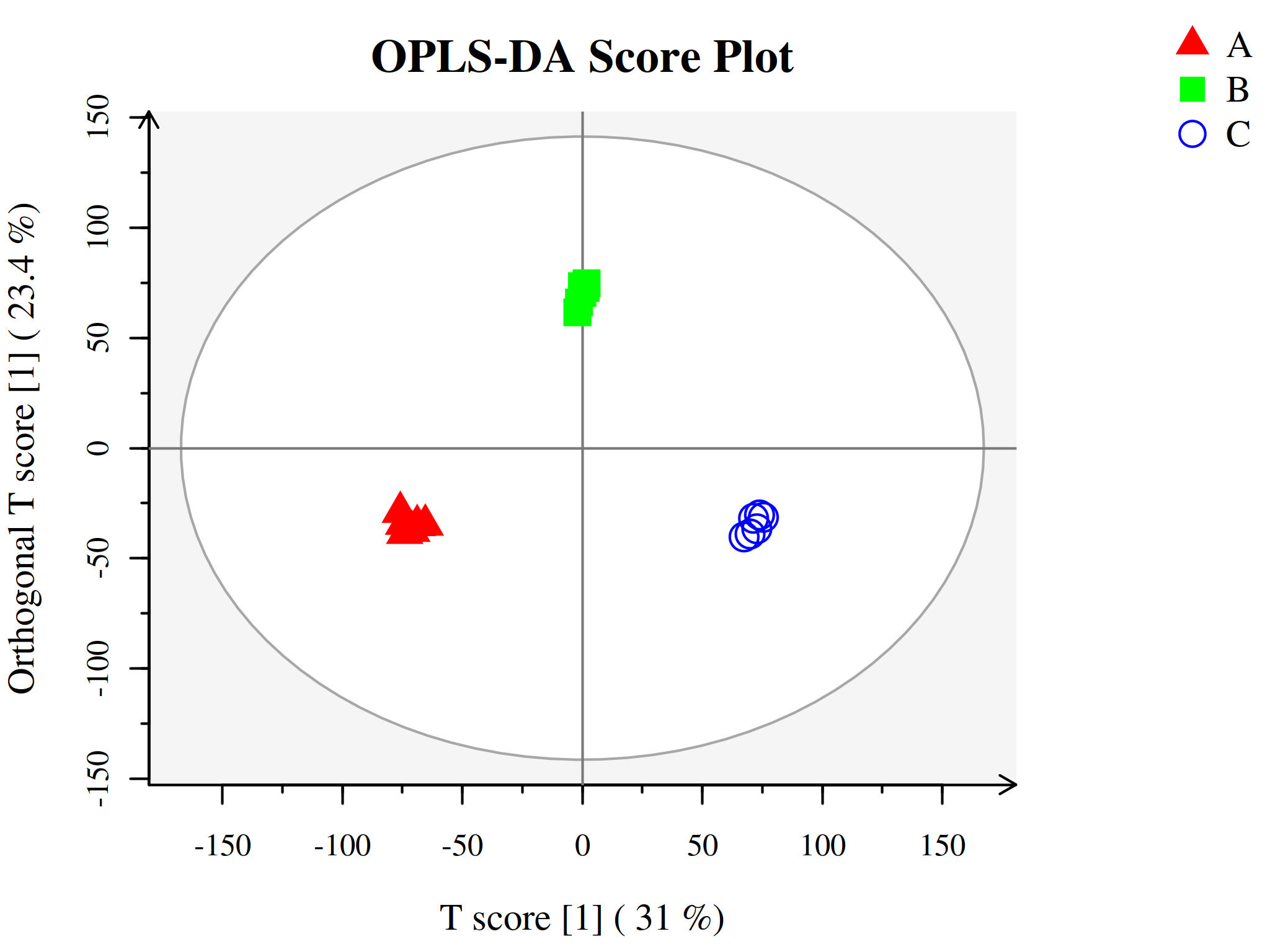
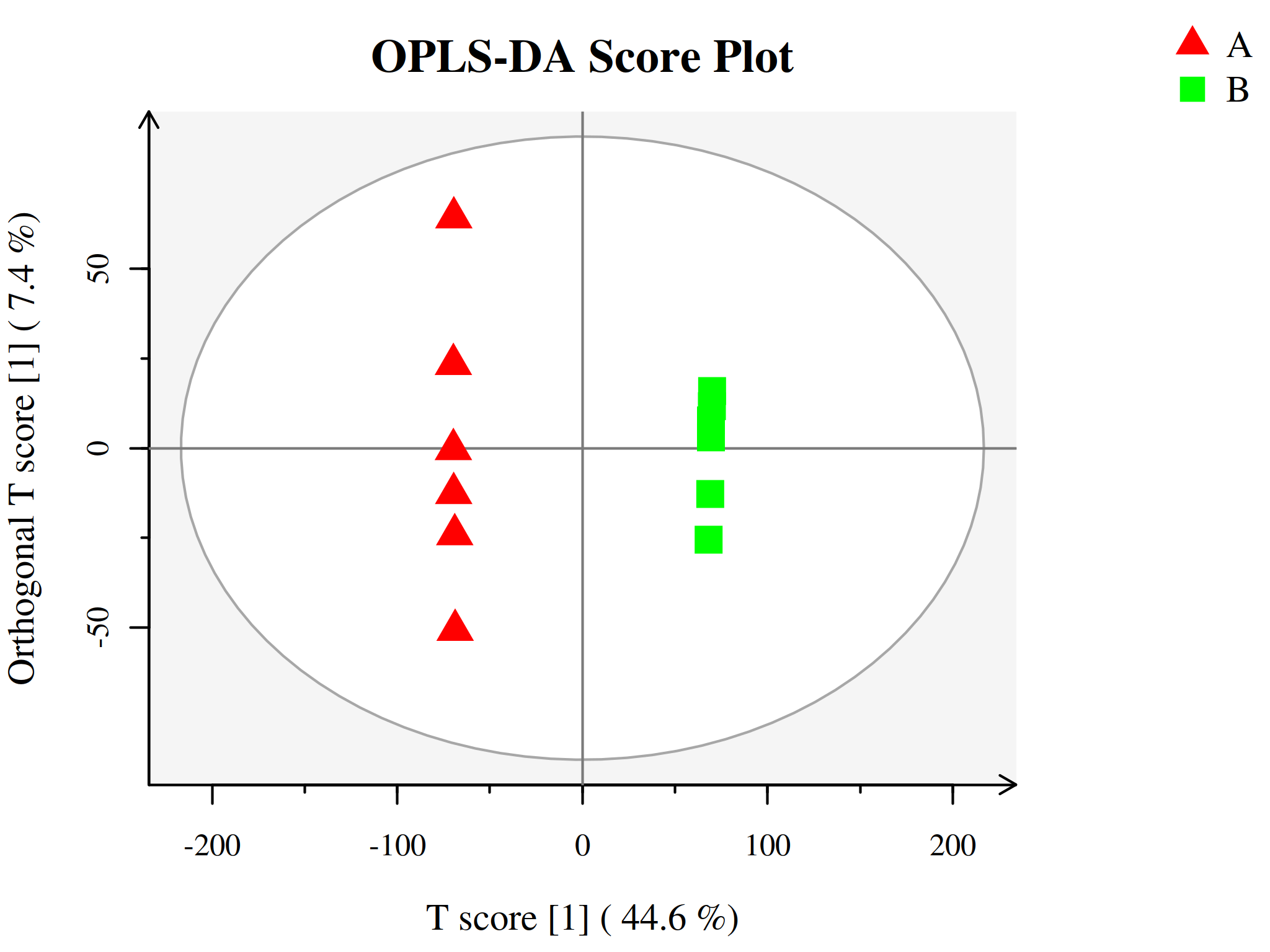
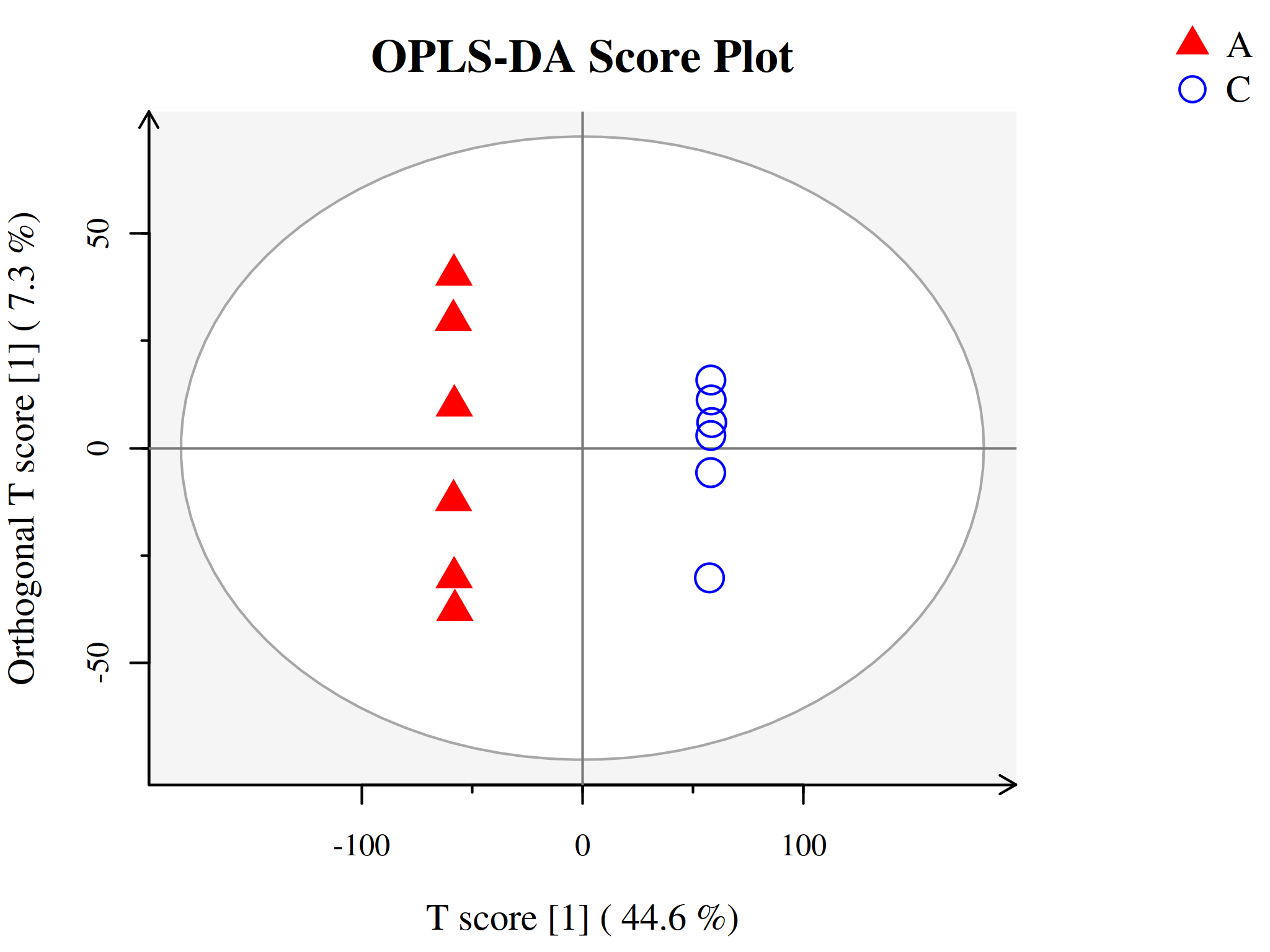
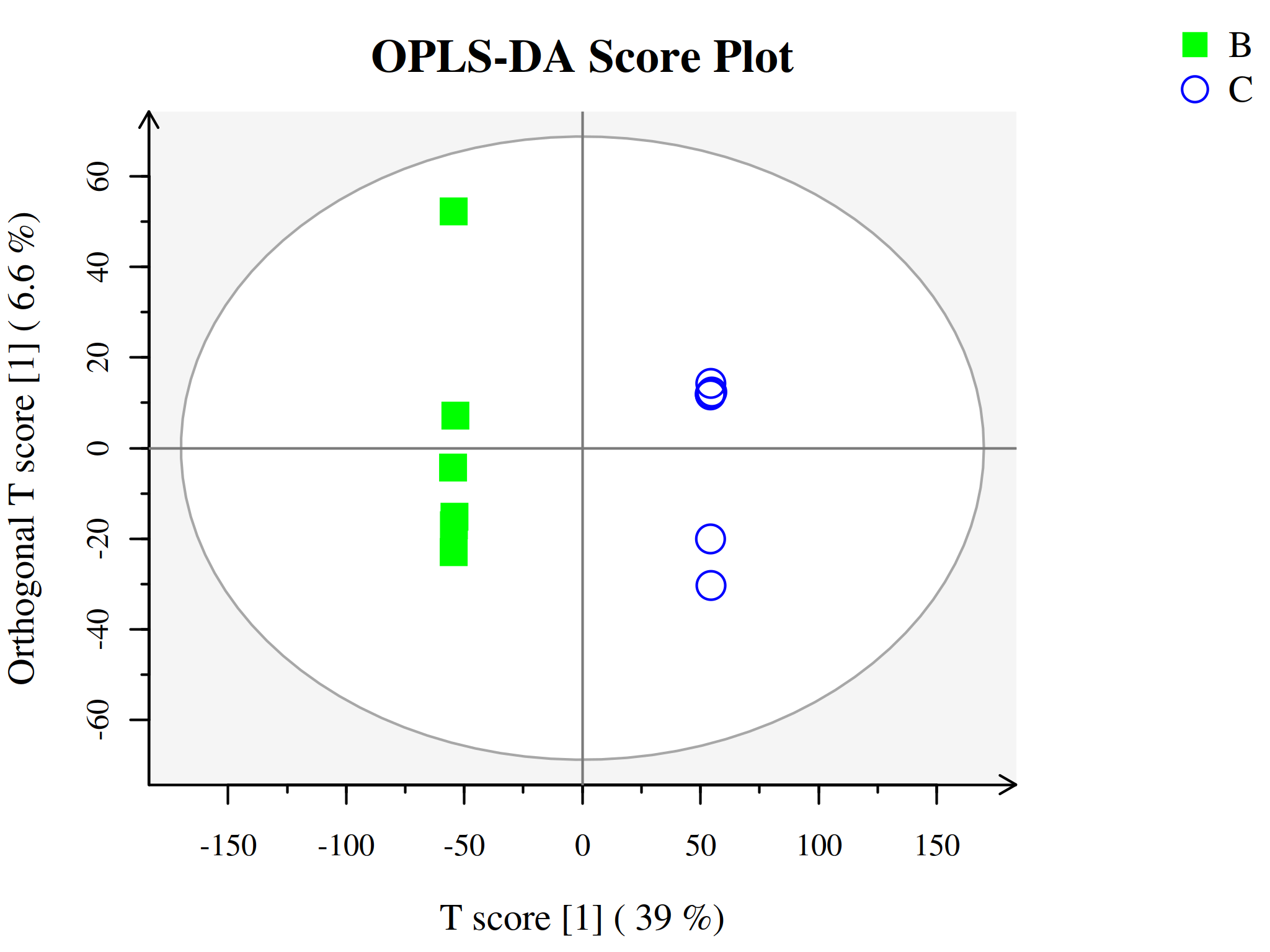
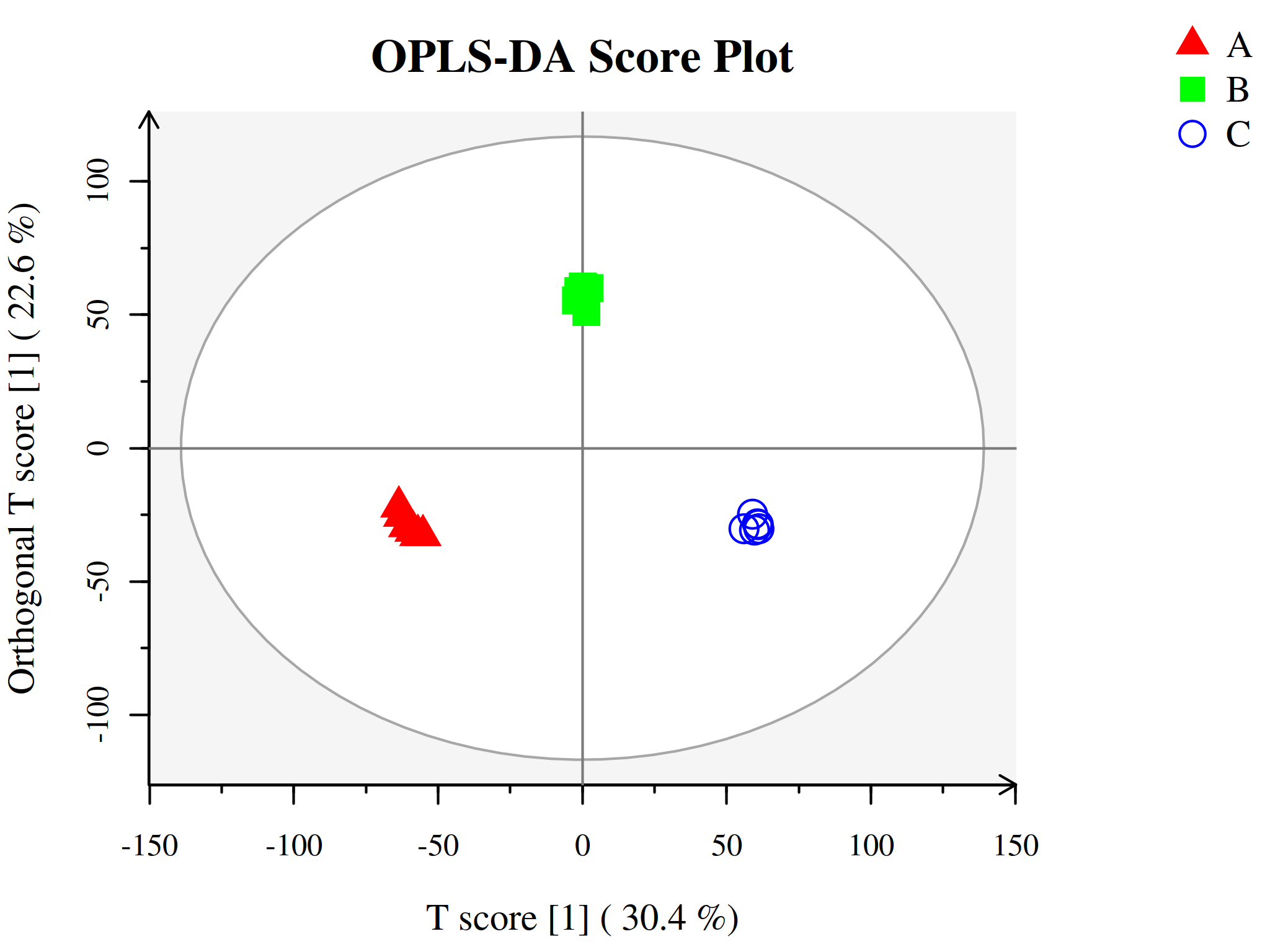
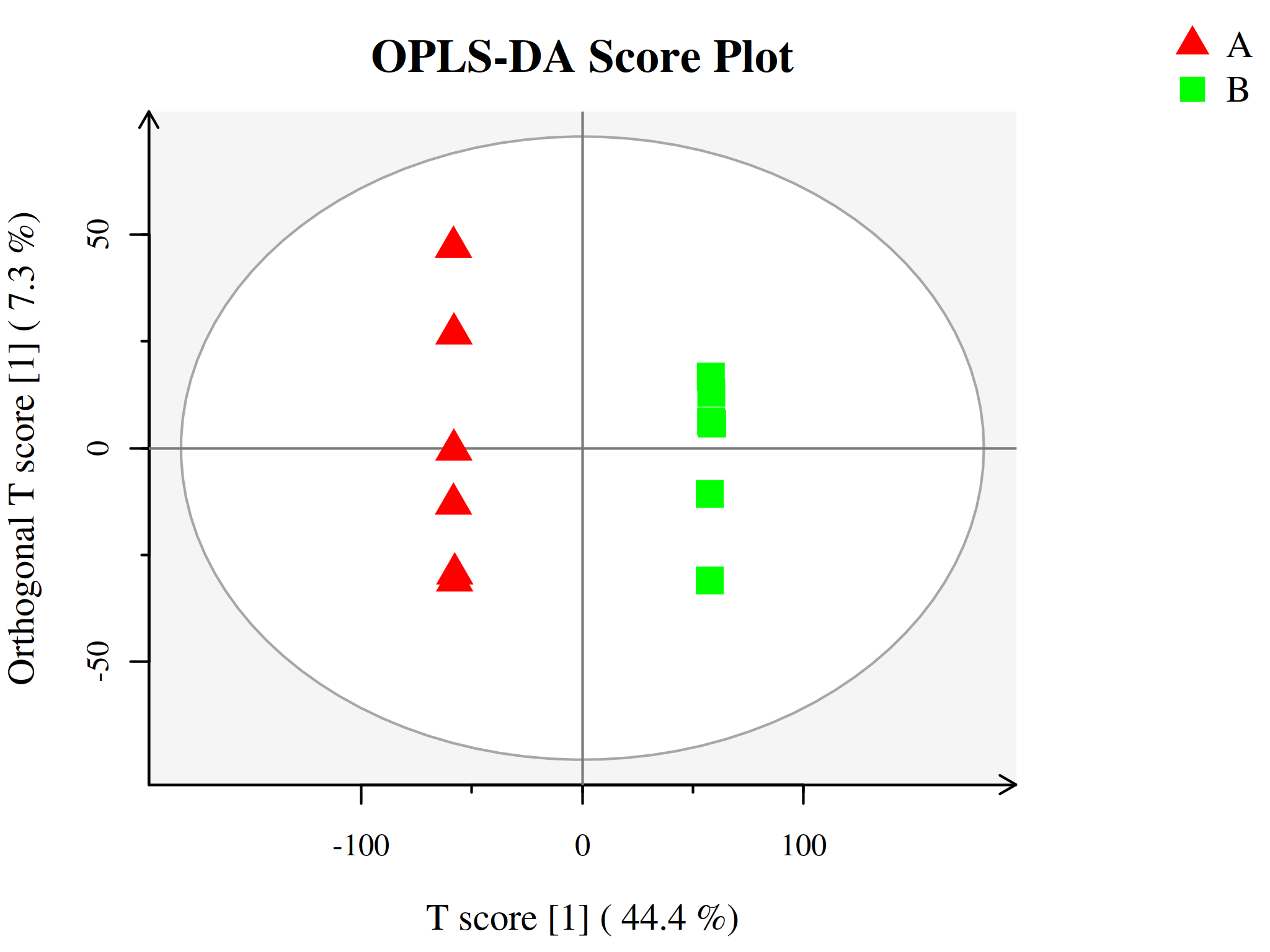
代谢组学数据分析中另一种常用的方法是正交-偏最小二乘判别分析(Orthogonal Projections to Latent Structures Discriminant Analysis, OPLS-DA),为PLS-DA的扩展。相比于PLS-DA,该方法可以在不降低模型预测能力的前提下,有效减少模型的复杂性和增强模型的解释能力,从而最大程度查看组间差异。
OPLS-DA使用正交信号校正技术,将X矩阵信息分解成与Y相关和不相关的两类信息,然后过滤掉与分类无关的信息,相关的信息主要集中在第一个预测成分。
与PLS-DA模型相同,OPLS-DA同样可以用R2X、R2Y、Q2和OPLS-DA得分图来评价模型的分类效果。
通常,根据VIP(Variable Importance for the Projection)值来说明变量(特征峰)能解释X数据集和关联Y数据集的重要性。所有VIP值的平方之和与模型中的变量总数相等,因此,其平均值为1[2]。
当某个变量的VIP>1时,说明该变量是重要的——通常将此作为潜在生物标记物的筛选条件之一。